Light-weight crypto: RabbitRabbit is a Light Weight Stream Cipher and was written by Martin Boesgaard, Mette Vesterager, Thomas Christensen and Erik Zenner. It creates a key stream from a 128-bit key and a 64-bit initialization vector [paper]: |
Outline
The methods we used for encryption, such as AES, are often not fit-of-purpose for devices which have limited storage and processing facilities. Thus newer methods are being investigated which are simpler to implement. Once of these is the Rabbit stream encryption method. With this we take a secret key and then generate an infinitely long cipher stream. The cipher key stream is then EX-OR’ed with the data stream. On the other side, we generate the same cipher key stream, and then EX-OR it with the inputting cipher stream, and thus recover the data stream. Nice and simple.
With this Bob must pass the secret key to Alice, for them both to create the same key stream. Along with this Bob needs to send the IV value used. If Eve is watching she will see the IV value, but will not know the secret key they have used:
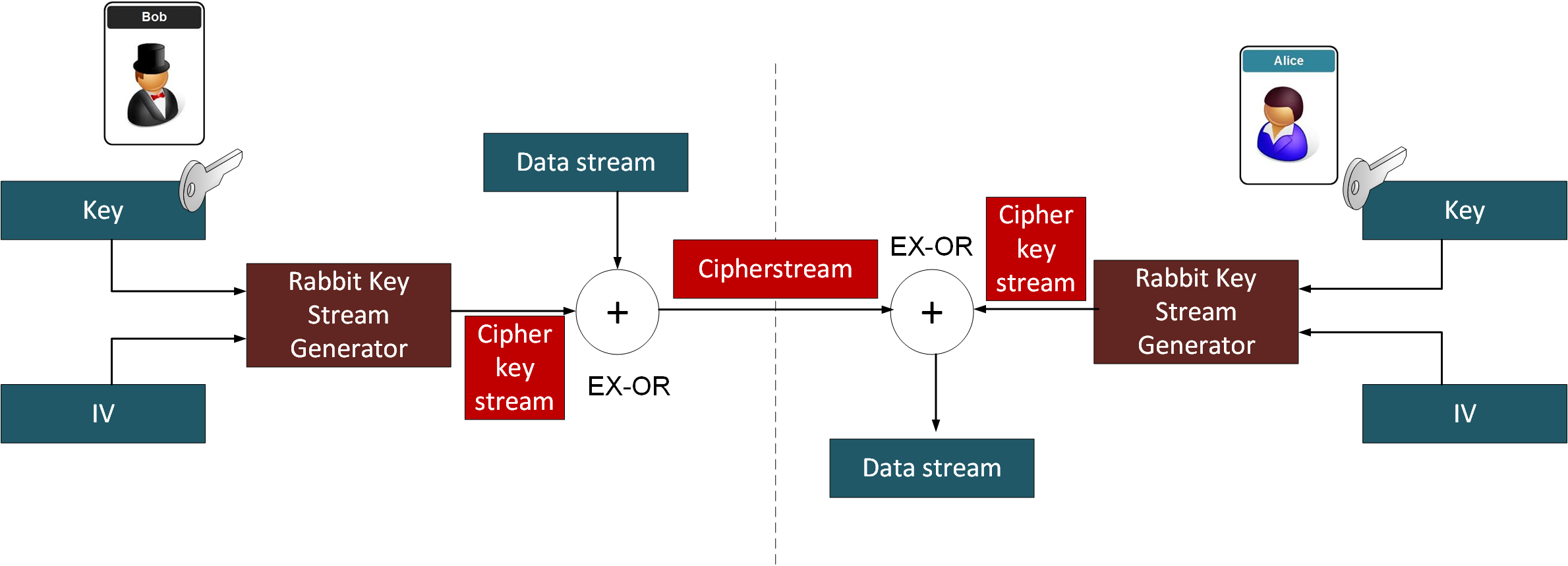
Rabbit is thus one contender for a light weight stream cipher and was written by Martin Boesgaard, Mette Vesterager, Thomas Christensen and Erik Zenner. It creates a key stream from a 128-bit key and a 64-bit initialization vector (IV) [paper]. The IV makes sure that the same plaintext does not appear as the same ciphertext.
Rabbit only needs 512 bits of storage space for the current state. There are eight counters (\(c_0\) — \(c_7\)) and eight states (\(x_0\) — \(x_7\)), and where the state number is defined as \(i\). Initially the key is loaded in the \(c_i\) and \(x_i\) registers. Next the IV value is applied with an EX-OR function to the \(c_i\) registers. After the initialization, each iteration performs after rotate left operations (<<<) on the state values:
The x values are then used to create eight state values, and which builds a 128-bit key stream block for each iteration of i. The 128-bit key stream block is then used to EX-OR with the data stream.
A sample run where a passphrase is converted into an 128-bit MD5 hash value is:
Message: abc Encryption password: qwerty Encryption key: d8578edf8458ce06fbc5bb76a58c5ca4 ======Rabbit encryption======== Encrypted: cf3548 Decrypted: abc
You can see that we have three bytes of an input (‘abc’), and that the output has also have three bytes (0xcf3548). A stream cipher is thus efficient in the processing, as there is no overhead in adding data (or padding bytes).
The code to implement this is:
import collections
import hashlib
import random
import rabbit
import binascii
import sys
def enc_long(n):
'''Encodes arbitrarily large number n to a sequence of bytes.
Big endian byte order is used.'''
s = ""
while n > 0:
s = chr(n & 0xFF) + s
n >>= 8
return s
WORDSIZE = 0x100000000
rot08 = lambda x: ((x << 8) & 0xFFFFFFFF) | (x >> 24)
rot16 = lambda x: ((x << 16) & 0xFFFFFFFF) | (x >> 16)
def _nsf(u, v):
'''Internal non-linear state transition'''
s = (u + v) % WORDSIZE
s = s * s
return (s ^ (s >> 32)) % WORDSIZE
class Rabbit:
def __init__(self, key, iv = None):
'''Initialize Rabbit cipher using a 128 bit integer/string'''
if isinstance(key, str):
# interpret key string in big endian byte order
if len(key) < 16:
key = '\x00' * (16 - len(key)) + key
# if len(key) > 16 bytes only the first 16 will be considered
k = [ord(key[i + 1]) | (ord(key[i]) << 8)
for i in range(14, -1, -2)]
else:
# k[0] = least significant 16 bits
# k[7] = most significant 16 bits
k = [(key >> i) & 0xFFFF for i in range(0, 128, 16)]
# State and counter initialization
x = [(k[(j + 5) % 8] << 16) | k[(j + 4) % 8] if j & 1 else
(k[(j + 1) % 8] << 16) | k[j] for j in range(8)]
c = [(k[j] << 16) | k[(j + 1) % 8] if j & 1 else
(k[(j + 4) % 8] << 16) | k[(j + 5) % 8] for j in range(8)]
self.x = x
self.c = c
self.b = 0
self._buf = 0 # output buffer
self._buf_bytes = 0 # fill level of buffer
next(self)
next(self)
next(self)
next(self)
for j in range(8):
c[j] ^= x[(j + 4) % 8]
self.start_x = self.x[:] # backup initial key for IV/reset
self.start_c = self.c[:]
self.start_b = self.b
if iv != None:
self.set_iv(iv)
def reset(self, iv = None):
'''Reset the cipher and optionally set a new IV (int64 / string).'''
self.c = self.start_c[:]
self.x = self.start_x[:]
self.b = self.start_b
self._buf = 0
self._buf_bytes = 0
if iv != None:
self.set_iv(iv)
def set_iv(self, iv):
'''Set a new IV (64 bit integer / bytestring).'''
if isinstance(iv, str):
i = 0
for c in iv:
i = (i << 8) | ord(c)
iv = i
c = self.c
i0 = iv & 0xFFFFFFFF
i2 = iv >> 32
i1 = ((i0 >> 16) | (i2 & 0xFFFF0000)) % WORDSIZE
i3 = ((i2 << 16) | (i0 & 0x0000FFFF)) % WORDSIZE
c[0] ^= i0
c[1] ^= i1
c[2] ^= i2
c[3] ^= i3
c[4] ^= i0
c[5] ^= i1
c[6] ^= i2
c[7] ^= i3
next(self)
next(self)
next(self)
next(self)
def __next__(self):
'''Proceed to the next internal state'''
c = self.c
x = self.x
b = self.b
t = c[0] + 0x4D34D34D + b
c[0] = t % WORDSIZE
t = c[1] + 0xD34D34D3 + t // WORDSIZE
c[1] = t % WORDSIZE
t = c[2] + 0x34D34D34 + t // WORDSIZE
c[2] = t % WORDSIZE
t = c[3] + 0x4D34D34D + t // WORDSIZE
c[3] = t % WORDSIZE
t = c[4] + 0xD34D34D3 + t // WORDSIZE
c[4] = t % WORDSIZE
t = c[5] + 0x34D34D34 + t // WORDSIZE
c[5] = t % WORDSIZE
t = c[6] + 0x4D34D34D + t // WORDSIZE
c[6] = t % WORDSIZE
t = c[7] + 0xD34D34D3 + t // WORDSIZE
c[7] = t % WORDSIZE
b = t // WORDSIZE
g = [_nsf(x[j], c[j]) for j in range(8)]
x[0] = (g[0] + rot16(g[7]) + rot16(g[6])) % WORDSIZE
x[1] = (g[1] + rot08(g[0]) + g[7]) % WORDSIZE
x[2] = (g[2] + rot16(g[1]) + rot16(g[0])) % WORDSIZE
x[3] = (g[3] + rot08(g[2]) + g[1]) % WORDSIZE
x[4] = (g[4] + rot16(g[3]) + rot16(g[2])) % WORDSIZE
x[5] = (g[5] + rot08(g[4]) + g[3]) % WORDSIZE
x[6] = (g[6] + rot16(g[5]) + rot16(g[4])) % WORDSIZE
x[7] = (g[7] + rot08(g[6]) + g[5]) % WORDSIZE
self.b = b
return self
def derive(self):
'''Derive a 128 bit integer from the internal state'''
x = self.x
return ((x[0] & 0xFFFF) ^ (x[5] >> 16)) | \
(((x[0] >> 16) ^ (x[3] & 0xFFFF)) << 16)| \
(((x[2] & 0xFFFF) ^ (x[7] >> 16)) << 32)| \
(((x[2] >> 16) ^ (x[5] & 0xFFFF)) << 48)| \
(((x[4] & 0xFFFF) ^ (x[1] >> 16)) << 64)| \
(((x[4] >> 16) ^ (x[7] & 0xFFFF)) << 80)| \
(((x[6] & 0xFFFF) ^ (x[3] >> 16)) << 96)| \
(((x[6] >> 16) ^ (x[1] & 0xFFFF)) << 112)
def keystream(self, n):
'''Generate a keystream of n bytes'''
res = ""
b = self._buf
j = self._buf_bytes
next = self.__next__
derive = self.derive
for i in range(n):
if not j:
j = 16
next()
b = derive()
res += chr(b & 0xFF)
j -= 1
b >>= 1
self._buf = b
self._buf_bytes = j
return res
def encrypt(self, data):
'''Encrypt/Decrypt data of arbitrary length.'''
res = ""
b = self._buf
j = self._buf_bytes
next = self.__next__
derive = self.derive
for c in data:
if not j: # empty buffer => fetch next 128 bits
j = 16
next()
b = derive()
res += chr(ord(c) ^ (b & 0xFF))
j -= 1
b >>= 1
self._buf = b
self._buf_bytes = j
return res
decrypt = encrypt
message="Hello"
key="qwerty"
iv=0
key1 = hashlib.md5(key.encode()).hexdigest()
print("Message:\t\t",message)
print("IV:\t",iv)
print("Encryption password:\t",key)
print("Encryption key:\t\t",key1)
print("\n======Rabbit encryption========")
iv=0
msg=Rabbit(key1,iv).encrypt(message)
print("Encrypted:\t",binascii.hexlify(msg.encode()))
text=Rabbit(key1,iv).decrypt(msg)
print("Decrypted:\t",text)
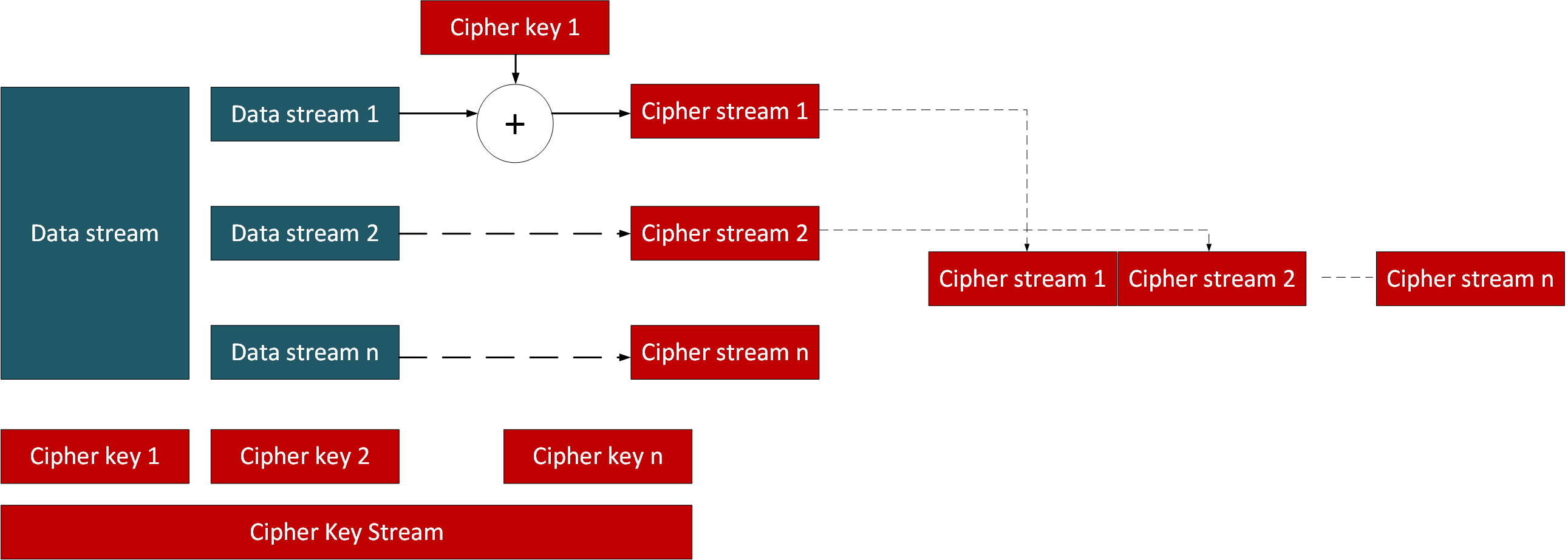
Overall Rabbit needs around 4,000 transistors, and a throughput of between 55MBit/s and 500MBit/s (using a carry look-ahead circuit). One of the great advantages of stream ciphers is that we take chunks of the key, and then process memory blocks in parallel, that they reconstruct for the cipher stream. This multiples up the throughput of a stream cipher, in a way that a chained block cipher could not deal with (as a block cipher needs to reconstruct the data stream in a chain fashion). It is thus possible to achieve throughputs of GBit/s, and also have virtually no latency on re-building the data.
Stream ciphers gets a bad name after the disaster of WEP, and where a 24-bit IV value was used (and which would roll-over within hours and reveal the plaintext). Also it used 40-bit RC4 encryption, and which can easily discovered by brute force (only 2⁴⁰ keys to search). A 128-bit key for Rabbit makes it robust against brute force attacks. It is also fairly simple to implement and requires minimal storage of states. Compared with AES for low-powered devices, it looks a winner. Up to now no weaknesses have been found in it, too.
For AES, we see weaknesses around side channel attacks and memory leakages. Here is a new paper we have just written on breaking the PRESENT light-weight crypto method, and which is based on the AES method [here].
Presentation
A presentation is here [slides]: