MD6 was submitted as a standard for the SHA-3 competition, and designed by a team of researchers including Ronald L. Rivest and Benjamin Agre. It uses a bottom-up tree-based mode using Merkle tree-like structure .
MD6 Hashing (Pumpkin Hash) |
 [
[Theory
Ron Rivest is held in possibly the highest of all regards of anyone in cryptography. He has been cited over 155,480 times, including:
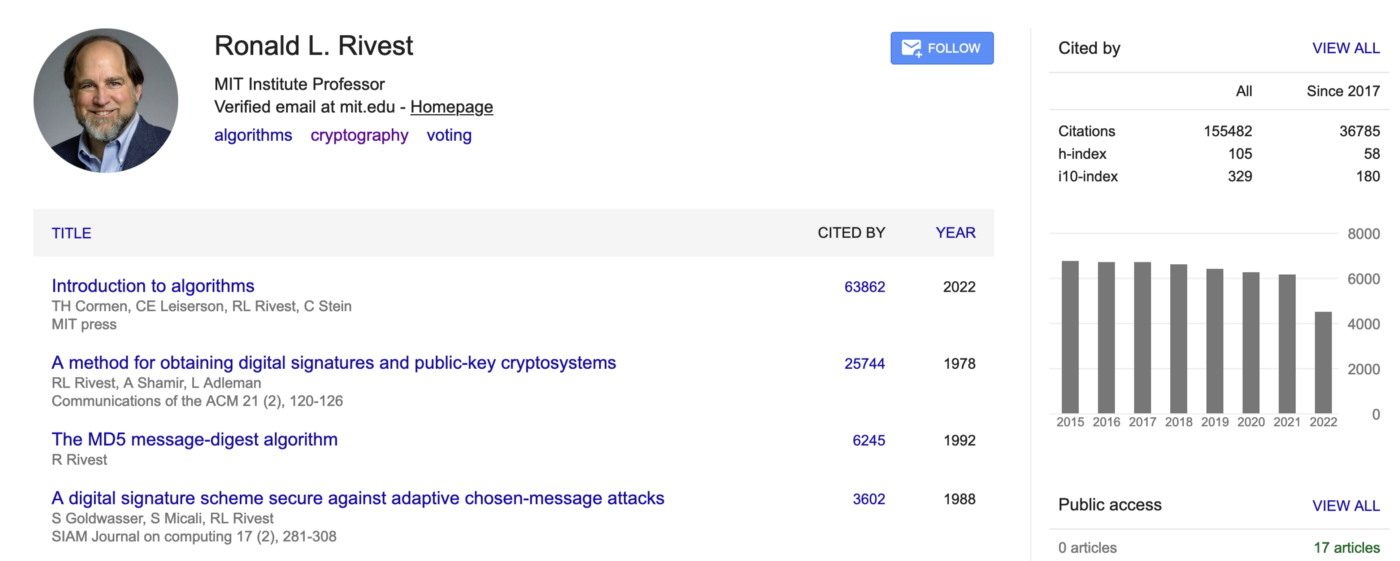
His classic paper was, of course, the RSA method ("A method for obtaining digital signatures and public-key cryptosystems"). RSA, in fact, still provides the core of trust on the Internet. But, he also published a classic paper on the MD5 hashing method. This produced a 128-bit hash value and was (and still is) well-used in many applications. Unfortunately, it is now fairly easy to create a hash collision.
And, so, all looked good for Ron to produce the next version of the hashing method — the MD6 method. It was at a time when NIST was standardizing the SHA-3 method, and so, he and several other authors submitted the MD6 hashing method to Round 1 [here]:

In a presentation, Ron referred to MD6 as the Pumpkin hash, as the submission date for SHA-3 submissions was Halloween 2008. While the Keccak sponge function eventually won the competition, MD6 was interesting as it used a Merkle tree-like to support a massively parallel hashing process. It was thought to be free from side channels and achieved hashing spends of 1GB/s using a 16-core CPU infrastructure.
Unfortunately, Douglas Held found a buffer overflow weakness, and Ron announced this in February 2009. While Ron never actually withdrew the hash, it did not make it to Round 2, he noted:
We are not withdrawing our submission; NIST is free to select MD6 for further consideration in the next round if it wishes. But at this point MD6 doesn’t meet our own standards for what we believe should be required of a SHA-3 candidate, and we suggest that NIST might do better looking elsewhere. In particular, we feel that a minimum “ticket of admission” for SHA-3 consideration should be a proof of resistance to basic differential attacks, and we don’t know how to make such a proof for a reduced-round MD6.
And, so, given such a strong statement, NIST did not select it to progress to Round 2. But, by 2011, though, an improved method was created that overcame the weakness [here]:

In 2008, MD5 entered the NIST competition along with 50 other candidates, with 14 progressing to Round 2. In the final round — Round 3 — there were only five candidates: BLAKE, Grøstl, JH, Keccak and Skein. The winner — Keccak — was announced in October 2021. Since then, though, BLAKE has gone from strength to strength, and BLAKE 3 is one of the fastest cryptographic hashing methods around.
MD6
We see Merkle trees in many application areas of blockchain. With this, we take two hashes of data at a time, and hash them together in order to create a root hash (Figure 1).
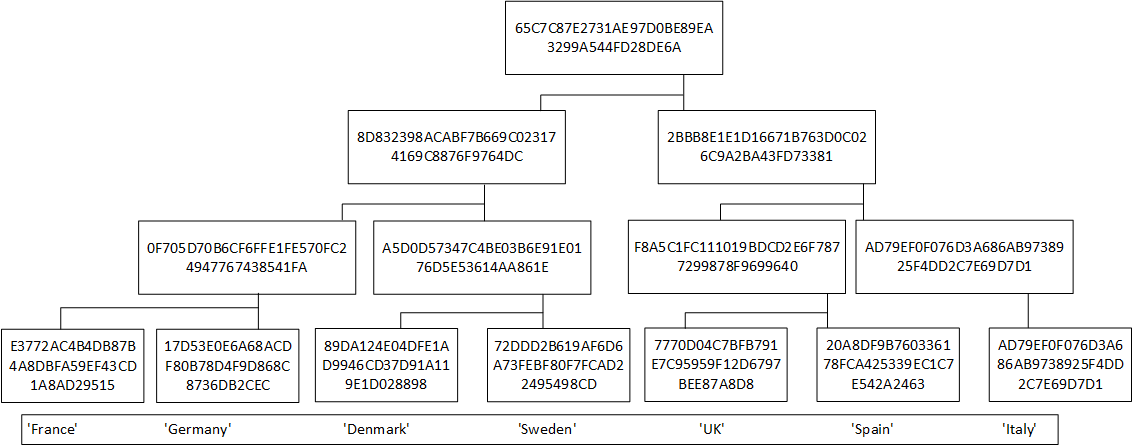
Figure 1: Merkle Tree
The great advantage of using a Merkle Tree is that we can easily check that a value is included in the root hash. In the diagram below, to test that ‘Germany’ (Node 2) is in the tree, we would need only need Node 1, Node 34 and Node 567 in order to generate the root (Node 1234567):
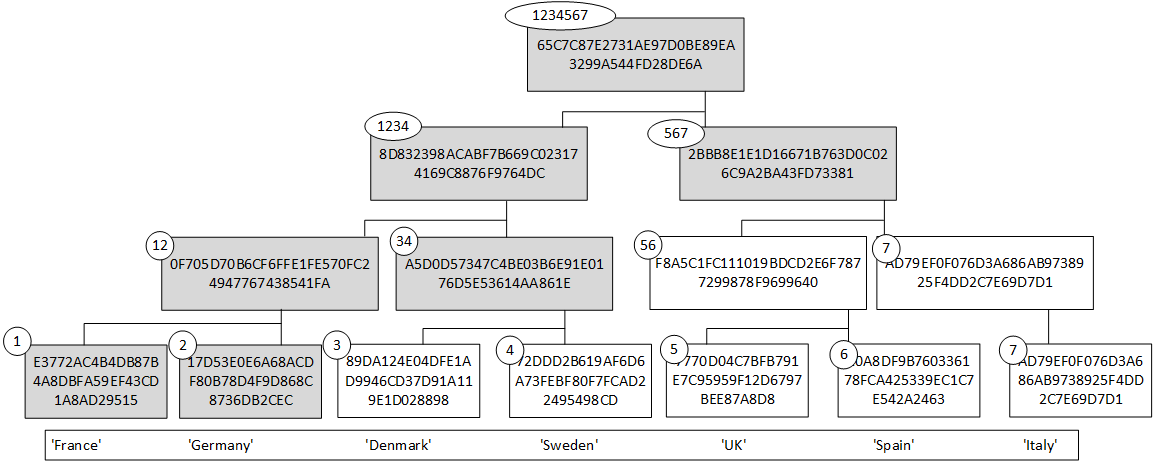
Figure 2: Merkle Tree
The reason we only need nodes 1, 34 and 567, is that we can regenerate Node 12 and Node 1234 from these values. Bitcoin, for example, uses this method in order to check the validity of a transaction within the block. We can then add our transactions into a Merkle Tree, and produce a root hash. Within the block, we can then add the root hash of the previous block and the root hash of the next block and thus interlock the blocks into a chain:
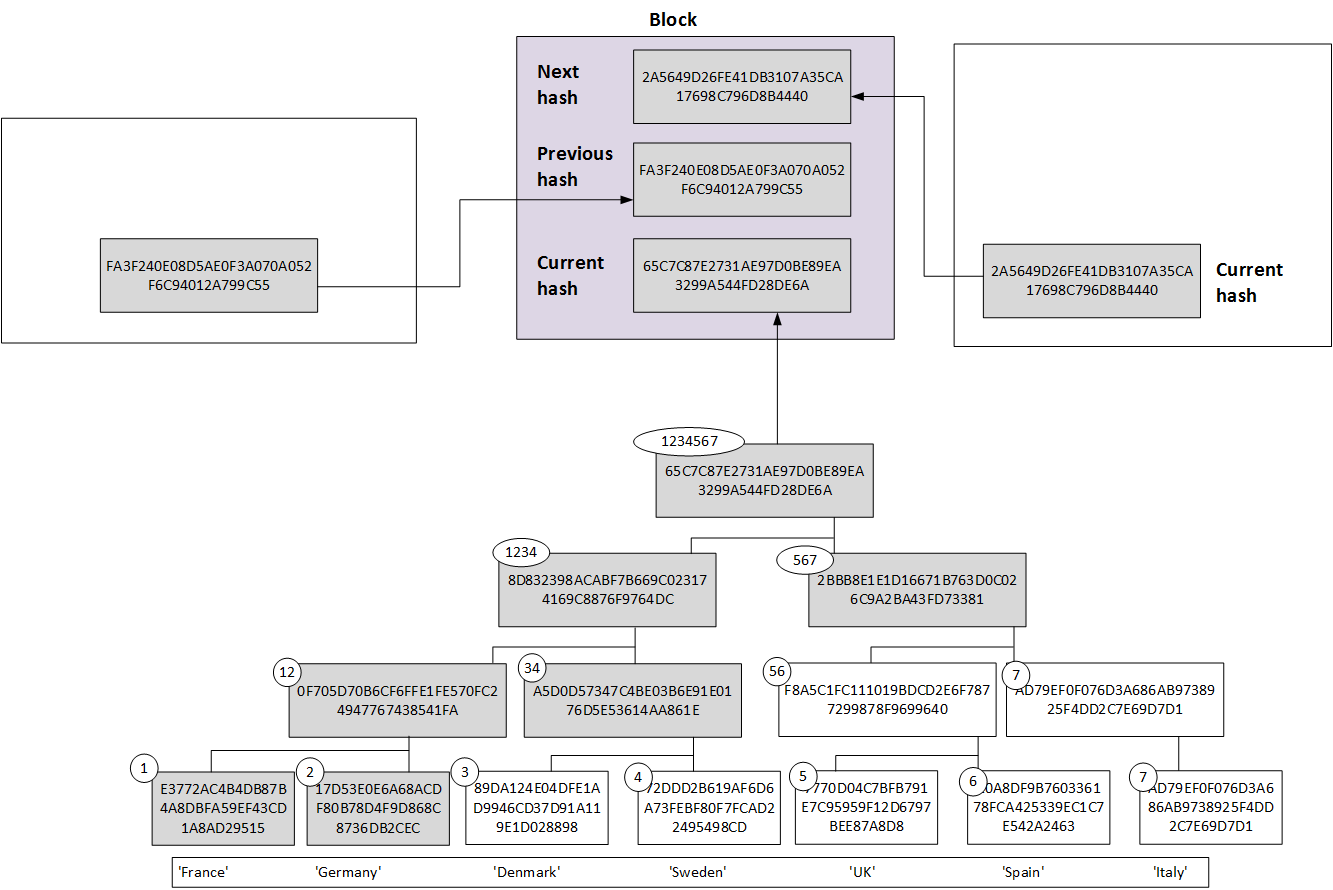
Figure 3
Ron’s idea was to use the power of the Merkle Tree to actually use the root hash as the overall hash of the data. The great advantage of this is that the lower layers of the tree can be done as a massively parallel operation, and where we can independently hash the lower levels at the same time (if we can multiple CPUs). In Figure 3, we see 1–2, 3–4, 5–6 and 6–7 can all be processed at the same time, and then 12–23 and 56–7. Ron proposed that this multiprocessing approach could take advantage of the rise in multi-processor systems.
For MD6, the input data size ranges from 0 to \(2^{64}–1\) bits, and the output hash is either 224, 256, 384, or 512 bits. One of its key strengths is its simplicity and its provable resistance of differential attacks. It uses a fairly large input message block size of 512 bytes (and which is much larger than most hashing methods). MD6 then uses the Merkle Tree to hash four blocks at a time, and thus achieves a 4–1 compression ratio at each level (Figure 4). Thus if we start 256x512 bytes (128MB) at Level 0, we will have 256 nodes. At Level 1, we will then have 64 nodes, and then at Level 2, we will have 16 nodes, and so on, until we get a final root hash. This root hash is then the MD6 hash of the data. The height of the tree can then be shown to be \(log_4(nodes)\). For 256 nodes, we get a height of eight.
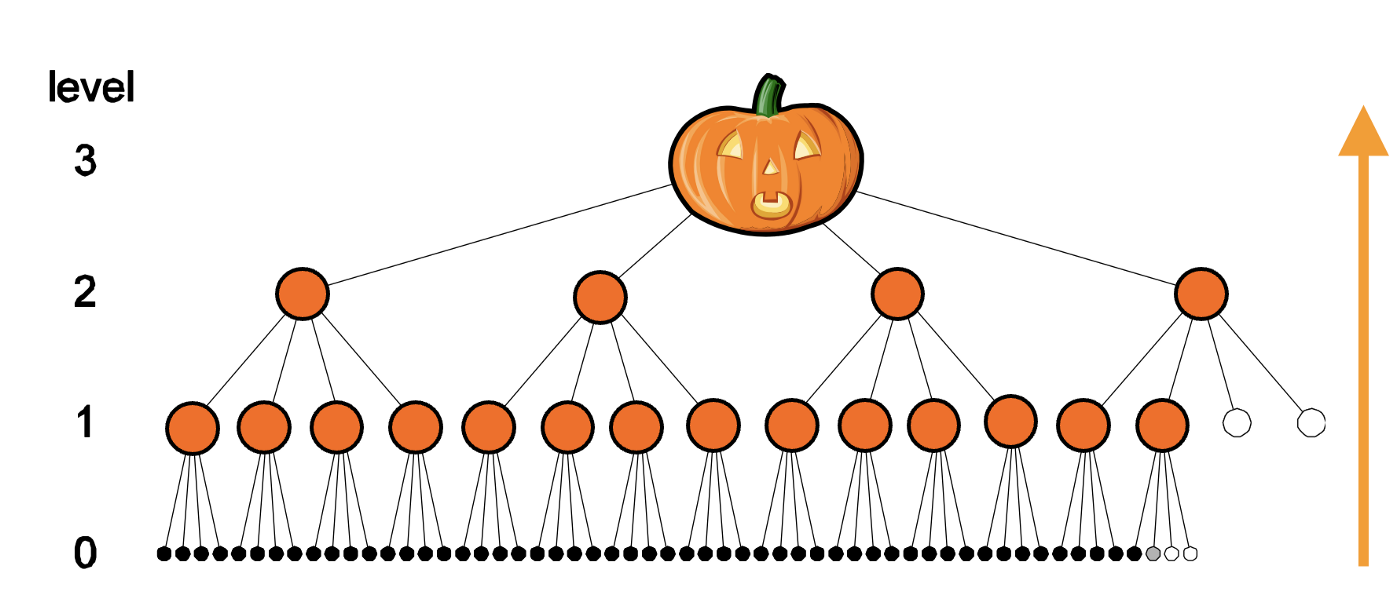
Figure 4 [here]
With MD6, we can significantly speed up the method using CPU cores to run the hashing of the tree, and illustrated in Figure 5.
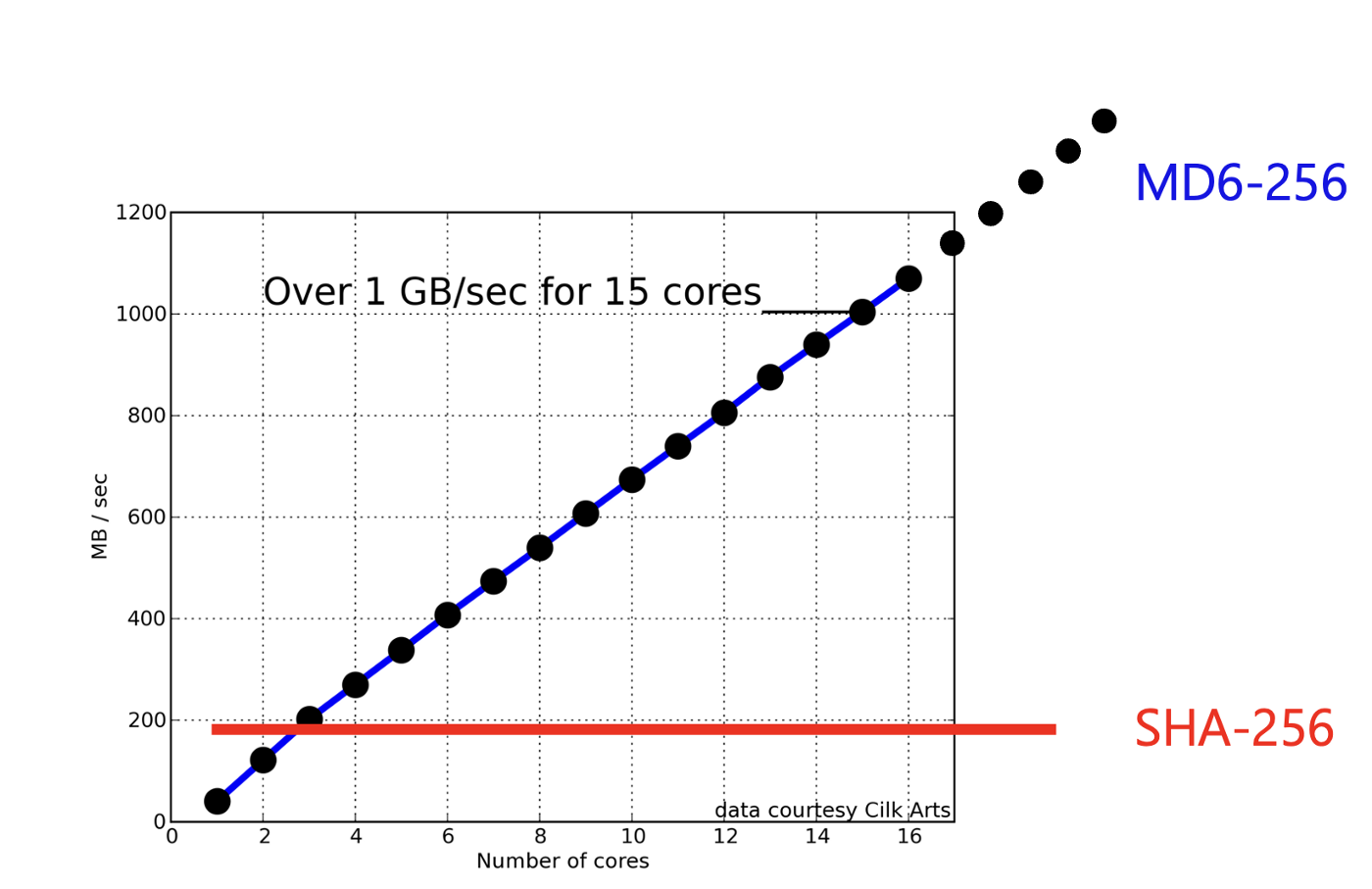
Figure 5 [here]
Coding
The following is some code to implement MD6 [using here code]:
var md6 = require("./md6.js");
var data = "Hello"
var args = process.argv;
if (args.length>1) data=args[2];
console.log("Message: " + data);
var hash = md6.getHashOfText(data,16*8);
console.log("Hash 128: " + hash);
var hash = md6.getHashOfText(data,32*8);
console.log("Hash 256: " + hash);
var hash = md6.getHashOfText(data,64*8);
console.log("Hash 512: " + hash);
A sample run is:
Message: Test Hash 128: bc7e7a90c6610310a6c386ba0482c889 Hash 256: 2543e1c393d880e4564fed11f15d03ade6c5ccb9dbbd45ff1808010cbd82bdd2 Hash 512: 702fd91632a6df15bb5041eb2ea031f7b931564eeb5324e92250bf2f4a8cb5eb7f40a607341b1ede16c880040bd04ab828f9aa81b5da3967111cdcdafd390839